AWS Solutions for Hybrid and Multicloud — Amazon Athena — Google BigQuery Integration
This is part of a series of personal blogs highlighting some of the AWS Solutions for Hybrid and Multicloud, which span Data and Analytics, cloud operations, security, observability and much more. This personal blog is meant to showcase the Amazon Athena connector for Google BigQuery which enables Amazon Athena to run SQL queries on Google BigQuery data.
While this blog showcases connector for Google BigQuery, Athena has many connectors for several data sources including Azure Synapse, Snowflake and many others.
This is a personal blog and written in a point of time and for a specific use-case, please refer to the official documentation on https://docs.aws.amazon.com/ and Google BigQuery for the authoritative and final view !!
Amazon Athena is an interactive query service that makes it easy to analyse data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. By taking a few steps in the AWS Management Console, you can direct Athena to your data stored in Amazon S3 and start using SQL to run on-the-spot queries and receive results within seconds. Interactively running data analytics with Apache Spark is made easy by Amazon Athena, with no need for resource planning, configuration, or management. When you run Apache Spark applications on Athena, you submit Spark code for processing and receive the results directly. Use the simplified notebook experience in Amazon Athena console to develop Apache Spark applications using Python or Athena notebook APIs.
Athena SQL and Apache Spark on Amazon Athena are serverless, so there is no infrastructure to set up or manage, and you pay only for the queries you run. Athena scales automatically — running queries in parallel — so results are fast, even with large datasets and complex queries.
Objective
Google BigQuery is a serverless enterprise data warehouse on the Google Cloud Platform. Using Athena data source connectors, we can query a variety of data sources external to Amazon S3. The Amazon Athena connector for Google BigQuery enables Amazon Athena to run SQL queries on Google BigQuery data. Follow this blog to set up the Amazon Athena connector for Google BigQuery and run SQL queries with results shown in the Amazon Athena console.
Athena uses data source connectors that run on AWS Lambda to run federated queries. A data source connector is a piece of code that can translate between your target data source and Athena. The complete lits of connectors can be found at https://docs.aws.amazon.com/athena/latest/ug/connectors-available.html

Pre-requisites
The Amazon Athena Google BigQuery connector page has details of the parameters that need to be set to establish connectivity to BigQuery. We need the following configuration information for the mandatory parameters:
Step 1: Create a private key on Google Cloud to access Google cloud services like BigQuery, and download the json key and keep it in a safe place. We will need to store this data in AWS Secrets Manager, and use it during the configuration of the Athena connector with Google BigQuery:

Store the data from the downloaded json file as a secret in AWS secrets manager


We will need the Secret Name of the secret key later for the parameter secret_manager_gcp_creds_name.
Step 2: Create a bucket in Amazon S3 for data that exceeds Lambda function limits, for data that exceeds Lambda function limit for the parameter spill_bucket
Step 3: We will need to get details of the Google BigQuery project ID, and we should have an sample dataset, table and data in BigQuery. You can refer to this documentation to get started with a sample dataset, table and load some sample data.
Amazon Athena configuration
Step 1: Create a new Data source for Google BigQuery in Amazon Athena in the AWS console.

Create a new Lambda function and enter the configuration information for SpillBucket, GCPProjectID, LambdaFunctionName and SecretNamePrefix



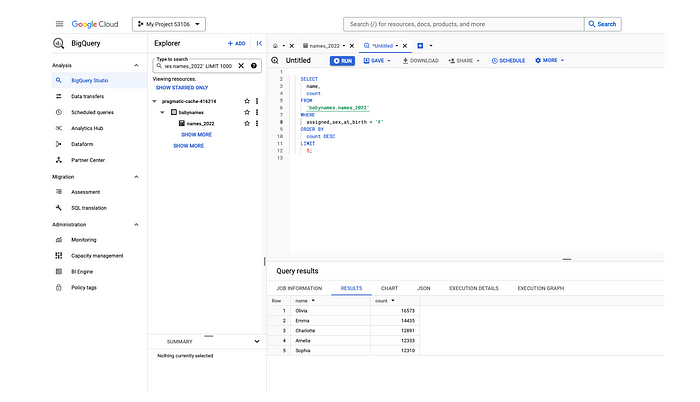
Step 2: If the configuration information for the BigQuery connector is correct, the connector should display the databases from Google BigQuery, in our case it picks the two datasets created by us in Google BigQuery, babynames and testathena1.

At this point, the configuration of the Athena BigQuery connector is complete and successful.
Amazon Athena — querying data on Google BigQuery
We can now issue the SQL queries from the Athena Query editor by selecting the BigQuery datasource and the database.

This matches the results from the Google BigQuery console !!

Note: Please consult the Amazon Athena Google BigQuery connector documentation on the limitations of the connector.
Hope this was useful. Please contact the AWS account team or myself, if you need more assistance. Thanks 🙏
Resources
- Amazon Athena Google BigQuery connector — https://docs.aws.amazon.com/athena/latest/ug/connectors-bigquery.html
- GitHub repository — https://github.com/awslabs/aws-athena-query-federation
- AWS blog — Multicloud data lake analytics with Amazon Athena
- Load and query data with the Google Cloud console — https://cloud.google.com/bigquery/docs/quickstarts/load-data-console
- Generic AWS Blog : Jeff Barr’s — AWS and Multicloud: Existing capabilities & continued enhancements
- Generic AWS Blog : Tom Godden — Proven Practices for Developing a Multicloud Strategy
